
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 고등 화법과 작문 교과서 e북 보기
- 고등 화법과 작문 교과서 pdf 다운로드
- 고등 화법과 작문 교과서 온라인 보기
- 천재 통합과학 교과서 e북
- 지학사 통합과학 교과서 pdf
- 지학사 e북
- 창비 화법과 작문 교과서 pdf 파일
- 화법과 작문 교과서 무료 다운로드
- 지학사 통합과학 교과서 e북
- 미래엔 화법과 작문 교과서 pdf
- 비상 통합과학 교과서 pdf
- 지학사 기술가정1 자습서 답지
- 화법과 작문 교과서 정식 e북 링크
- 지학사 고1기술가정
- 지학사 기술가정2 교과서 pdf
- 비상교육 화법과 작문 교과서 다운로드
- 비상 통합과학 교과서 e북
- 지학사 고1기술가정 교과서 pdf
- 지학사 화법과 작문 교과서 원본 파일
- 통합과학 교과서 pdf
- 지학사 교과서 e book
- 천재 통합과학 교과서 pdf
- 지학사 기술가정1 교과서 pdf
- 지학사 교과서 e북
- 지학사 e북 링크
- 미래엔 통합과학 교과서 e북
- 천재교육 화법과 작문 교과서 e북
- 미래엔 통합과학 교과서 pdf
- 동아 통합과학 교과서 pdf
- 지학사 기술가정2
- Today
- Total
교과서 자료실
판다스 pandas 데이터 시각화 matplotlib python 활용 본문
활용데이터 #01 : 기상청 https://data.kma.go.kr
1907년 10월 1일 ~ 2018년 3월 28일까지의 서울의 평균기온, 최저기온, 최고기온 자료가 담긴 csv

seoul.csv
seoul.csv
활용데이터 #02 : 행안부 https://jumin.mois.go.kr/
전국 지역별 인구 자료와 2019년 남녀 지역,연령별 성비 자료

age.csv

gender.csv
1. csv의 모든 내용 출력
import csv #csv모듈 임포트
f = open('.\data\seoul.csv', 'r') #서울csv를 리드 모드로 불러옴
#f = open('.\data\seoul.csv') #읽기모드(read)는 생략 가능
data = csv.reader(f, delimiter = ',')# 구분자를 ',' 기준으로 불러옴
#data = csv.reader(f) #구분자 정보 생략 가능
for row in data:
print(row)
f.close() #파일을 열었으면 잘 닫자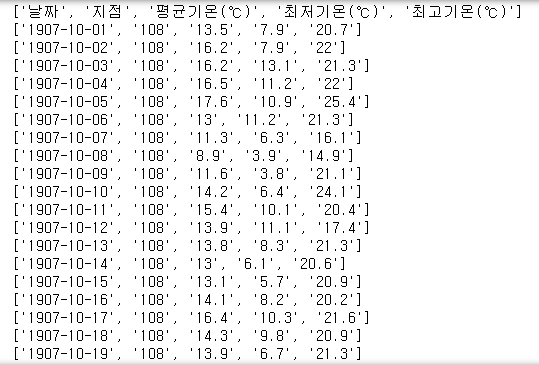
2. 헤더의 정보를 빼고 출력
#헤더의 정보를 빼고 출력
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
#next() 첫 번째 데이터 행을 읽어오면서 데이터의 탐색 위치를
# 다음행으로 이동시키는 명령어
#헤더에는 컬럼, 도메인이라고 db쪽에서 지칭
header = next(data)
for row in data:
print(row)
f.close()
3. 헤더의 정보만 출력
#헤더의 정보만 출력
#헤더(header): 데이터 파일에서 여러가지 값들이 어떤 의미를 갖는지
# 표시하는 행을 말합니다.
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
header = next(data)
print(header)
f.close()['날짜', '지점', '평균기온(℃)', '최저기온(℃)', '최고기온(℃)']
4. 서울의 가장 더웠던 날을 출력
import csv
max_temp = -999 #최고 기온 값을 저장할 변수
max_date = '' #최고 기온이 가장 높았던 날짜를 저장할 변수
f = open('.\data\seoul.csv')
data = csv.reader(f)
#next() 첫 번째 데이터 행을 읽어오면서 데이터의 탐색 위치를
# 다음행으로 이동시키는 명령어
#헤더에는 컬럼, 도메인이라고 db쪽에서 지칭
header = next(data)#헤더의 정보를 빼고 출력
for row in data:
if row[-1] == "":
row[-1] = -999
row[-1] = float(row[-1])#최고 기온을 실수로 변환
if max_temp < row[-1]: #만약 지금까지 최고 기온값보다 현재 행의 최고 기온 값이 더 크다면
max_temp = row[-1] #최고 기온을 업데이트
max_data = row[0] #최고 기온 날짜를 업데이트
f.close()
#만약 지금까지 최고 기온값보다 현재 행의 최고 기온값이 더 크다면
#최고 기온 날짜를 업데이트
#최고 기온 값을 업데이트
print(max_data, max_temp)1994-07-24 38.4
5. 서울의 가장 추웠던 날을 출력
#헤더의 정보를 빼고 출력
import csv
min_temp = 999 #최저 기온 값을 저장할 변수
min_date = '' #최저 기온이 가장 높았던 날짜를 저장할 변수
f = open('.\data\seoul.csv')
data = csv.reader(f)
#next() 첫 번째 데이터 행을 읽어오면서 데이터의 탐색 위치를
# 다음행으로 이동시키는 명령어
#헤더에는 컬럼, 도메인이라고 db쪽에서 지칭
header = next(data)
for row in data:
if row[-1] == "":
row[-1] = 999
row[-1] = float(row[-1])#최고 기온을 실수로 변환
if min_temp > row[-1]: #만약 지금까지 최고 기온값보다 현재 행의 최고 기온 값이 더 크다면
min_temp = row[-1] #최고 기온을 업데이트
min_date = row[0] #최고 기온 날짜를 업데이트
f.close()
#만약 지금까지 최고 기온값보다 현재 행의 최고 기온값이 더 크다면
#최고 기온 날짜를 업데이트
#최고 기온 값을 업데이트
print(min_date, min_temp)1915-01-13 -16.3
matplotlib를 활용한 그래프 그리기
1. 기본 선형 그래프
import matplotlib.pyplot as plt
plt.plot([10,20,30,40])
plt.show()
2. plot([list_a],[list_b]) #plot에서는 첫번째 리스트가 x축, 두번째 리스트가 y축을 나타낸다
import matplotlib.pyplot as plt
plt.plot([1,2,3,4], [12,43,25,15])#첫번째 리스트가 x축, 두번째 리스트가 y축
plt.show()
3. 그래프의 타이틀 넣기
plt.title('plotting')#그래프의 타이틀
plt.plot([10,20,30,40])
plt.show()
4. 범례표시 넣기
plt.title('legend')#타이틀은 legend 로 지정
plt.plot([10,20,30,40], label = 'asc') #상승라인은 asc로 지정
plt.plot([40,30,20,10], label = 'desc') #하강라인은 desc로 지정
plt.legend()#범례표시 호출
plt.show()
5. 그래프의 컬러 변경
plt.title('color')
plt.plot([10,20,30,40], color = 'skyblue', label = 'skyblue')
plt.plot([40,30,20,10], 'pink', label = 'pink')
plt.legend()#범례표시 호출
plt.show()
6. 라인의 스타일 변경
plt.title('linestyle')
plt.plot([10,20,30,40], color = 'r', linestyle = '--', label = 'dashed')
plt.plot([40,30,20,10], 'g', ls = ':', label = 'dotted')
plt.legend()#범례표시 호출
plt.show()
7. 그래프에 마커 표시
plt.title('marker')
plt.plot([10,20,30,40], 'r.--', label = 'circle')#색상, 마커모양, 선모양(r.--)
plt.plot([40,30,20,10], 'g^', label = 'triangle up')
plt.legend()#범례표시 호출
plt.show()
데이터 분석과 시각화 활용
1. 최고 기온 데이터 출력한 뒤 그래프로 표현
#최고 기온 데이터 출력하기
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
result = [] #최고 기온 데이터 저장할 리스트 생성
for row in data:
#print(row[-1])
#만약 빈문자('')가 아니라면 리스트에 저장
if row[-1] != '':
result.append(float(row[-1]))
f.close()
#print(len(result))
plt.figure(figsize = (10, 2)) #그래프의 가로길이를 10인치 세로를 2인치로 설정
plt.plot(result, 'r')
plt.show()
2. 매년 8월의 최고기온을 추출해서 그래프로 표현
#1년 중 여름의 정점인 8월의 최고 기온 데이터만 추출해서 그래프로 그려보세요.
#색상은 hotpink로 지정합니다.
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
result = [] #최고 기온 데이터 저장할 리스트 생성
for row in data:
if row[-1] != '':
month = row[0].split('-')[1]
if month == '08':
result.append(float(row[-1]))
f.close()
import matplotlib.pyplot as plt
#plt.figure(figsize = (10, 2)) #그래프의 가로길이를 10인치 세로를 2인치로 설정
plt.plot(result, 'hotpink')
plt.show()
3. 매년 11월 11일의 최고 기온 데이터를 추출하려 그래프로 표현
#매년 11월 11일의 최고 기온 데이터를 추출하여 그래프로 나타내시오
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
result = [] #최고 기온 데이터 저장할 리스트 생성
for row in data:
if row[-1] != '':
birth = row[0].split('-')[1] + row[0].split('-')[2]
if birth == '1111':
result.append(float(row[-1]))
f.close()
import matplotlib.pyplot as plt
#plt.figure(figsize = (10, 2)) #그래프의 가로길이를 10인치 세로를 2인치로 설정
plt.plot(result, 'r')
plt.show()
4. 매년 크리스마스의 최고 기온 데이터와 최저 기온 데이터를 추출하여 그래프로 표현
* 한글 폰트 지정 및 - 숫자 정보가 깨질 경우 해결
#매년 크리스마스의 최고 기온 데이터와 최저 기온 데이터를 추출하여 그래프로 나타내시오
#최고기온 데이터: hotpink
#최저기온 데이터: skyblue
#1980 이후 데이터를 기준으로 합니다.
#타이틀: 매년 크리스마스의 기온 변화 그래프
#범례: 최고 기온 - high, 최저기온 - low
#글꼴: Malgun Gothic
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
result_high = [] #최고 기온 데이터 저장할 리스트 생성
result_low = [] #최저 기온 데이터 저장할 리스트 생성
for row in data:
if row[-1] != '':
birth = row[0].split('-')[1] + row[0].split('-')[2]
if birth == '1225' and row[0].split('-')[0] >= '1980':
result_high.append(float(row[-1]))
result_low.append(float(row[-2]))
f.close()
import matplotlib.pyplot as plt
# 한글 폰트 사용을 위해서 세팅
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False #그래프 - 깨지는 현상해결
font_path = "C:/Windows/Fonts/malgun.ttf"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
#plt.figure(figsize = (10, 2)) #그래프의 가로길이를 10인치 세로를 2인치로 설정
plt.title("매년 크리스마스의 기온 변화 그래프")
plt.plot(result_high, 'hotpink', label = 'high')
plt.plot(result_row, 'skyblue' , label = 'low')
plt.legend()#범례표시 호출
plt.show()
히스토그램
히스토그램은 자료의 분포 상태를 직사각형 모양의 막대그래프로 나타낸 것으로
데이터의 빈도에 따라 높이가 결정
1. 히스토그램 기본
import matplotlib.pyplot as plt
plt.hist([1,1,2,3,4,5,6,7,8,10])
plt.show()
2. 주사위를 500번 던져서 나온 랜덤 1~6까지의 수를 11개 구획으로 나누어 히스토그램으로 시각화
#문제: 주사위를 500번 굴리시오
import random
dice = []
for i in range(500):
num = random.randint(1,6)
dice.append(num)
print(dice)
import matplotlib.pyplot as plt
plt.hist(dice, bins = 11) #데이터의 분포를 나타냄 bins는 구간을 11으로 현재 나눈 상태
plt.show()
3. 1907년부터 2018년까지 수집된 서울의 기온데이터를 히스토그램으로 표시
- 색은 red, 구간은 100개
#1907년 부터 2018년까지 수집된 서울의 기온 데이터를 히스토그램으로 표시하시오.
#색은 빨간색
#구간은 100개로 나누시오.
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
result = []
for row in data:
if row[-1] != '':
result.append(float(row[-1]))
f.close()
import matplotlib.pyplot as plt
#plt.figure(figsize = (10, 2)) #그래프의 가로길이를 10인치 세로를 2인치로 설정
plt.hist(result,color = 'r', bins = 100) #데이터의 분포를 나타냄 bins는 구간을 100으로 현재 나눈 상태
plt.show()
4. 8월의 데이터만 추출하여 히스토그램으로 시각화
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
aug = []
for row in data:
month = row[0].split('-')[1]
if row[-1] != '':
if month == '08': #08월의 데이터만 추출
aug.append(float(row[-1]))
f.close()
import matplotlib.pyplot as plt
plt.hist(aug,color = 'r', bins = 100) #데이터의 분포를 나타냄 bins는 구간을 100으로 현재 나눈 상태
plt.show()
5. 1월과 8월의 데이터를 히스토그램으로 표시
- 범례:1월 -> Jan, 8월 -> Aug
- 색상 : 1월 -> blue, 8월 -> red
- 구간 : 100개
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
jan = []
aug = []
for row in data:
month = row[0].split('-')[1]
if row[-1] != '':
if month == '08':
aug.append(float(row[-1]))
if month == '01':
jan.append(float(row[-1]))
f.close()
import matplotlib.pyplot as plt
plt.hist(aug,color = 'red', label = 'Aug', bins = 100)
plt.hist(jan,color = 'blue', label = 'Jan', bins = 100)
plt.legend()#범례표시 호출
plt.show()
상자그림(boxplot)
상자그림은 가공하지 않은 자료를 그대로 이용하는 것이 아니라, 자료에서 얻어낸 최대값, 최소값, 상위 1/4, 2/4(중앙), 3/4에 위치한 값을 보여주는 그래프
1. boxplot 기본 표현
import matplotlib.pyplot as plt
import random
result = []
for i in range(13):
result.append(random.randint(1,1000))
print(sorted(result))
plt.boxplot(result)
plt.show()
2. 서울의 최고기온 데이터를 boxplot으로 표시
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
result = []
for row in data:
if row[-1] != '':
result.append(float(row[-1]))
f.close()
import matplotlib.pyplot as plt
plt.boxplot(result)
plt.show()
3. 서울의 1월과 8월의 최고기온 데이터를 boxplot으로 표시
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
jan = []
aug = []
for row in data:
month = row[0].split('-')[1]
if row[-1] != '':
if month == '08':
aug.append(float(row[-1]))
if month == '01':
jan.append(float(row[-1]))
f.close()
import matplotlib.pyplot as plt
plt.boxplot([jan, aug])
plt.show()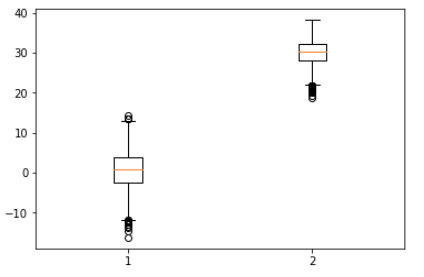
4. 서울의 최고기온 데이터를 월별로 구분하여 boxplot으로 표시
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
month = [[],[],[],[],[],[],[],[],[],[],[],[]] #12개의 리스트를 담은 리스트 생성
for row in data:
mon = float(row[0].split('-')[1])
if row[-1] != '':
#월과 같은 번호의 인덱스에 월별 데이터 저장,
month[int(row[0].split('-')[1]) - 1].append(float(row[-1]))
f.close()
import matplotlib.pyplot as plt
plt.boxplot(month)
plt.show()
5. 서울 8월의 일별 기온데이터를 boxplot으로 표시
import csv
f = open('.\data\seoul.csv')
data = csv.reader(f)
next(data)
day = []
for i in range(31):#day라는 리스트안에 31개의 리스트를 확장
day.append([])
for row in data:
d = float(row[0].split('-')[1])
if row[-1] != '' and d == 8:
#월과 같은 번호의 인덱스에 월별 데이터 저장
day[int(row[0].split('-')[2]) - 1].append(float(row[-1]))
f.close()
import matplotlib.pyplot as plt
plt.boxplot(day)
plt.show()
6. 8월 일별 기온데이터를 boxplot으로 표시
- 그래프스타일을 지정, 가로 세로 사이즈와 dpi, 결측치 제거
import csv
f = open('.\\data\\seoul.csv')
data = csv.reader(f)
next(data)
day = []
for i in range(31):
day.append([])
for row in data:
if row[-1] != '':
if row[0].split('-')[1] == '08':
day[int(row[0].split('-')[2])-1].append(float(row[-1]))
f.close()
import matplotlib.pyplot as plt
plt.style.use('ggplot') #그래프 스타일을 지정
plt.figure(figsize = (10,2), dpi = 300) #그래프 크기 수정
plt.boxplot(day, showfliers = False) #결측치(범위를 벗어난 수치),다른 말로 아웃라이어 값을 생략 -> showfiliers = False
plt.show()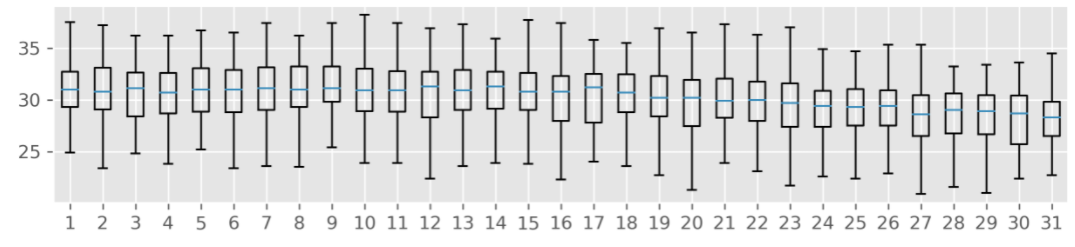
age.csv 데이터 확인
1. age.csv 내용 출력
import csv
f = open('.\\data\\age.csv')
data = csv.reader(f)
for row in data:
print(row)
f.close() #열었으면 잘 닫기
2. 서울 명동의 데이터 확인
import csv
f = open('.\\data\\age.csv')
data = csv.reader(f)
for row in data:
if '서울특별시 중구 명동(1114055000)' == row[0]: #줄의 첫번째 값이 '서울특별시 중구 명동(1114055000)'와 같은 것 출력
print(row)
f.close()
격자무늬 스타일로 그래프 그리기
1. 신도림의 0세부터 100세이상 까지 인구수를 격자무늬 스타일 그래프로 시각화
import csv
f = open('.\\data\\age.csv')
data = csv.reader(f)
result = []#빈 리스트
for row in data:
if '신도림' in row[0]: #'신도림'이 포함된 행정구역 찾기
print("충 구간은 {}입니다.".format(len(row[3:])) )
for i in row[3:]: #0세부터 100세이상까지 모든 연령에 대해 반복하기
result.append(int(i))#애당 연령의 인구수 리스트에 순서대로 저장하기
f.close()
print(result)#0세부터 100세이상까지의 인구수 출력하기
import matplotlib.pyplot as plt
plt.style.use('ggplot')#격자무늬 스타일 저장
plt.plot(result)
plt.show()
2. 인구구조가 알고 싶은 지역의 이름(읍면동 단위)를 입력해 시각화
import csv
f = open('.\\data\\age.csv')
data = csv.reader(f)
result = []
name = input('인구 구조가 알고 싶은 지역의 이름(읍면동 단위)을 입력해주세요 :')
for row in data:
if name in row[0]:
for i in row[3:] :
#result.append(int(i.replace(',','')))
result.append(int(i))
import matplotlib.pyplot as plt
# 한글 폰트 사용을 위해서 세팅
from matplotlib import font_manager, rc
plt.rc('font', family = 'Malgun Gothic') #맑은 고딕을 기본 글꼴로 설정
plt.rcParams['axes.unicode_minus'] = False #그래프 - 깨지는 현상해결
plt.title("{} 지역의 인구 구조".format(name))
plt.style.use('ggplot')#격자무늬 스타일 저장
plt.plot(result)
plt.show()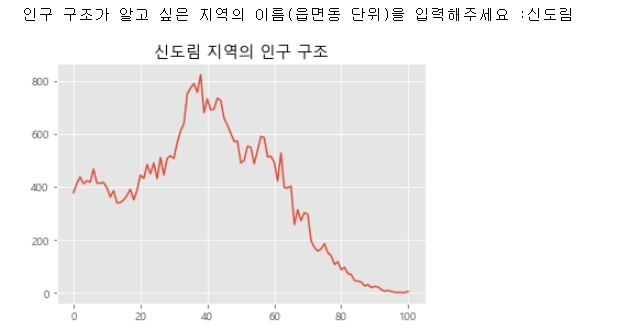
막대그래프(bar)
bar() 함수는 막대그래프를 표현하는 명령어입니다.
막대그래프에서 막대의 길이는 각 데이터의 크기를 의미합니다.
1. 막대그래프 기본
import matplotlib.pyplot as plt
#첫번째는 막대를 표시할 위치 #두번째는 막대의 높이, 개수가 일치해야 함
plt.bar([0,1,2,4,6,10],[1,2,3,5,6,7])
plt.show()
2. 오름차순 막대그래프
import matplotlib.pyplot as plt
plt.bar(range(6), [1,2,3,5,6,7])
plt.show()
3. 신도림 인구구조 막대그래프
import csv
f = open('.\\data\\age.csv')
data = csv.reader(f)
result = []
for row in data:
if '신도림' in row[0]:
for i in row[3:]:
result.append(int(i))
f.close()
import matplotlib.pyplot as plt
plt.bar(range(101), result)
plt.show()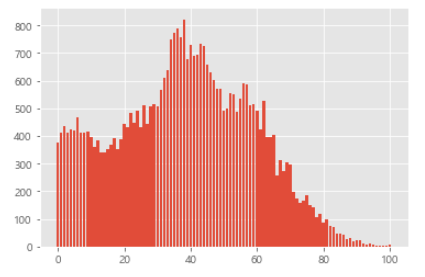
4. 수평 막대그래프 plt.barh()
import csv
f = open('.\\data\\age.csv')
data = csv.reader(f)
result = []
for row in data:
if '신도림' in row[0]:
for i in row[3:]:
result.append(int(i))
f.close()
import matplotlib.pyplot as plt
plt.barh(range(101), result) #수평으로 그리기
plt.show()
5. 신도림 지역의 남녀 성별 인구 분포
import csv
file = open('.\\data\\gender.csv')
data = csv.reader(file)
f = [] #여성 인구정보를 담을 리스트
m = [] #남성 인구정보를 담을 리스트
for row in data:
if '신도림' in row[0]:
for i in row[3:104]:#1에서 100까지
m.append(-int(i)) #남성데이터는 3~103
for i in row[106:]:
f.append(int(i)) #여성데이터는 106~206번까지
import matplotlib.pyplot as plt
# 한글 폰트 사용을 위해서 세팅
from matplotlib import font_manager, rc
plt.rc('font', family = 'Malgun Gothic') #맑은 고딕을 기본 글꼴로 설정
plt.rcParams['axes.unicode_minus'] = False #그래프 - 깨지는 현상해결
plt.title('신도림 지역의 남녀 성별 인구 분포')
plt.barh(range(101), m, label = '남성')
plt.barh(range(101), f, label = '여성')
plt.legend()
plt.show()
file.close()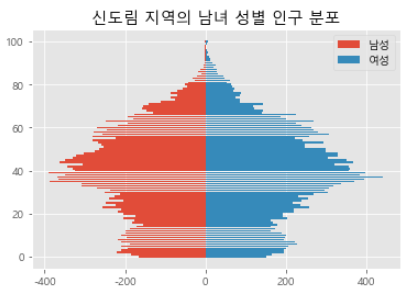
원 그래프 (파이차트)
pie()함수는 전체 데이터 중 특정 데이터의 비율을 보기 쉽게 표현하기 위해 쓰임
1. 기본 파이차트
import matplotlib.pyplot as plt
# 한글 폰트 사용을 위해서 세팅
from matplotlib import font_manager, rc
plt.rc('font', family = 'Malgun Gothic') #맑은 고딕을 기본 글꼴로 설정
plt.rcParams['axes.unicode_minus'] = False #그래프 - 깨지는 현상해결
size = [2441, 2312, 1031, 1233]
label = ['A형','B형','AB형','O형']#레이블
color = ['darkmagenta', 'deeppink', 'hotpink', 'pink']
plt.axis('equal')#동그란 원 -axis() 3시방향부터 반시계로
plt.pie(size, labels = label, autopct = '%.1f%%', colors = color, explode = (0,0,0.1,0)) #autopct -> 오토퍼센트, 비율
plt.legend()
plt.show()
꺾은선 그래프
1. 원하는 지역의 연령대별 인구를 꺾은선 그래프로 표시
import csv
f = open('.\\data\\gender.csv') #데이터 경로
data = csv.reader(f) #데이터 불러오기
male = [] #남녀 인구수를 저장할 빈 리스트 생성
female = [] #남녀 인구수를 저장할 빈 리스트 생성
name = input('찾고 싶은 지역의 이름을 알려주세요: ') #지역 이름 입력받기
for row in data:
if name in row[0]: #name과 일치하는 지역 찾기
for i in row[3:104]:#1에서 100까지
male.append(int(i)) #남성데이터는 3~103
for i in row[106:]:
female.append(int(i)) #여성데이터는 106~206번까지
break #첫번째 것만 출력하고 반복 종료
f.close()#csv파일 닫기
import matplotlib.pyplot as plt #시각화를 위한 matplotlib모듈 임포트
plt.rc('font', family = 'Malgun Gothic') #맑은 고딕을 기본 글꼴로 설정
plt.rcParams['axes.unicode_minus'] = False #그래프 - 깨지는 현상해결
#plt.style.use('ggplot')#격자무늬 스타일 저장
plt.plot(male, label = '남성', color = 'b')
plt.plot(female, label = '여성', color = 'r')
plt.legend()
plt.title(name + '지역의 연령대별 성별 인구') #제목설정하기
plt.show()
산점표
산점표는 가로축과 세로축을 기준으로 두 요소가 어떤 관계를 맺고 있는지 파악하기 쉽게 나타낸 그래프
scatter() 함수 사용
1. 산점도 그래프 기본
import matplotlib.pyplot as plt
plt.style.use('ggplot') #가시성을 위해 격자무늬 스타일 사용
#plt.scatter([1,2,3,4], [10,30,20,40], s = [100,200,250,300], c = ['r','b','g','gold']) #s는 사이즈, 버블차트를 나타내기 위함
plt.scatter([1,2,3,4], [10,30,20,40], s = [100,200,250,300], c = range(4), cmap = 'jet') #4개의 범위에 컬러바를 쓰겠다 c = range(4), cmap = 'jet'
plt.colorbar()
plt.show()
2. 산점도 그래프 기본2
- 랜덤함수를 활용 임의로 데이터 수치를 늘려서 적용
import matplotlib.pyplot as plt
import random
plt.style.use('ggplot') #가시성을 위해 격자무늬 스타일 사용
x = []
y = []
size = []
for i in range(100):
x.append(random.randint(50, 100))
y.append(random.randint(50, 100))
size.append(random.randint(10, 100))
plt.scatter(x,y,s = size, c = size, cmap = 'jet' , alpha = 0.7)
plt.colorbar()
plt.show()
3. 원하는 지역의 연령대별 성별 비율을 산점도로 표시
import math
import csv
f = open('.\\data\\gender.csv') #데이터 경로
data = csv.reader(f) #데이터 불러오기
male = [] #남녀 인구수를 저장할 빈 리스트 생성
female = [] #남녀 인구수를 저장할 빈 리스트 생성
size = []
name = input('찾고 싶은 지역의 이름을 알려주세요: ') #지역 이름 입력받기
for row in data:
if name in row[0]:
for i in range(3, 104):
male.append(int(row[i]))
female.append(int(row[i+103]))
size.append(math.sqrt(int(row[i])+int(row[i+103]))) #math.sqrt 제곱근을 넣어준 이유는 데이터 수치가 방대하게 올라가는 것을 방지하기 위함
break
import matplotlib.pyplot as plt #시각화를 위한 matplotlib모듈 임포트
plt.rc('font', family = 'Malgun Gothic') #맑은 고딕을 기본 글꼴로 설정
plt.style.use('ggplot')
plt.figure(figsize = (10,5), dpi = 300) #사이즈와 dpi 지정
plt.title(name + ' 지역의 성별 그래프')
plt.scatter(male, female, s = size, c = range(101), alpha = 0.5, cmap = 'jet')
plt.colorbar() #산점도 컬러차트 표시
plt.plot(range(max(male)), range(max(male)), 'g') #추세선 추가
plt.xlabel('남성인구수') #가로축 정보 표시
plt.ylabel('여성인구수') #세로축 정보 표시
plt.show()
f.close()